

Last weekend I took part in History Hack Day. I've been wanting to reboot the Computus Engine for a while and what better excuse than this. As a Hack Day newbie I wasn't sure what to expect but the natives were very friendly and I had a lot of fun. The Hack Day format works like this. A group of like minded individuals get together to hack/create a new (usually online) project in a short space of time - in our case about a day and a half. Sleep it seems, is optional.
The event was held in the offices of The Guardian newspaper in London. It was well organised (thank you Matt) and surprisingly well catered (thank you sponsors for the Square Mile Coffee). The format has been around for a while but Saturday's hack was the first time it has been applied to history. This event drew a nice mix of museum professionals, data wranglers and Hack Day regulars. Developer reps were also on hand from Google, Yahoo and Facebook.

The day opened with a series of short talks around the subject of history on the web. Hack Day organiser Matt Peterson began with some personal memories from his native Tipton. He also gave us one of the key observations of the day: we don't have any more information these days than we used to, it's just more accessible.

Quite a few of the attendees I met seemed to be ex-BBC employees. One of this alumni was Max Gadney (and Jake) who offered some insights around the problem of presenting high resolution data on a timeline. He also brought up the hot topic of data curation, or the pros and cons of drawing out specific data to tell a story. His advice is to find an accessible way into the data, "find an epic way in".

Tom Pollard of the British Library introduced us to their datasets programme. The aim of the programme is to improve access to the data usually locked inside academic journals. They are working towards this through a series of initiatives to aid citation, discovery, access and [re]use.
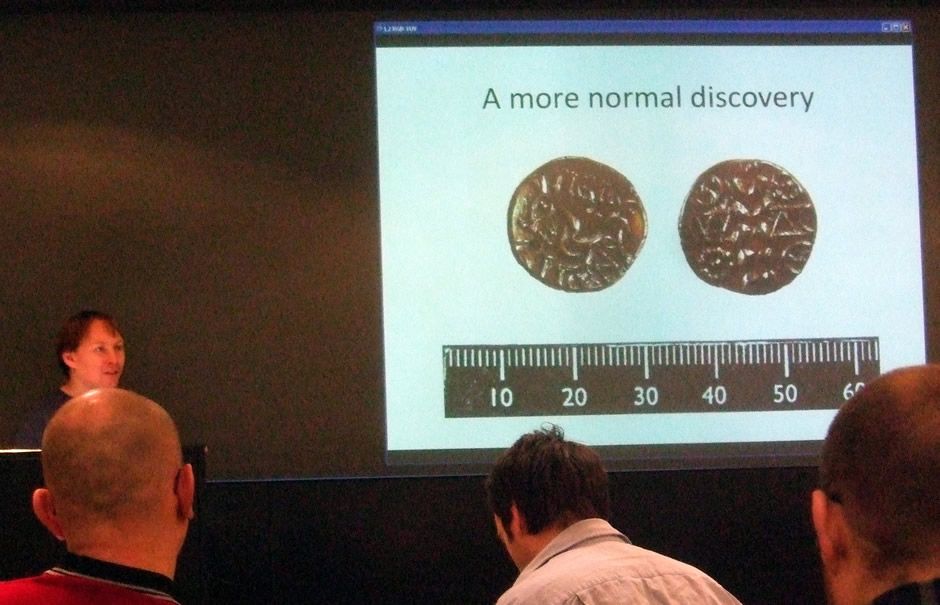
Dan Pett from the British Museum runs the website for the delightfully named Portable Antiquities Scheme. An archaeologist by training Dan taught himself web development as a response to his department's shrinking IT budget. The current iteration of the website cost just £48 to build. Much of the site content is user generated and then enhanced by innovative use of open APIs, (not-so-open) site-scraping and YQL. Important and inspiring work.
Next up, from the tech community, representatives from Google and Yahoo presented on Fusion Tables and YQL respectively. Fusion Tables are basically Google spreadsheets for dataviz. They are incredibly easy to work with (honestly, I think managers could use them) and they support charting, mapping and Simile timelines. Yahoo's YQL is essentially SQL for APIs. It's data wrangling middleware, but very useful for getting the data you want in the format you need. I'm not a data guy but I found both talks very enlightening.

Jo Pugh of the National Archives gave the morning's penultimate presentation. He talked about digitising the archive and the scale of the task. The National Archive has over 11 million records stretching back hundreds of years and much of that material is hand-written.
LastFM's "Data Griot" Matt Sheret was last to speak and he left us with an inspirational jaunt though history, storytelling, SpaceLog and of course Dr Who. One quote, "we leave messages for tomorrow" really stuck with me.


Duly inspired the attendees split off into groups and began brainstorming. Being something of a noob at the Hack Day thing I missed this rather important bit (I was enjoying the coffee again) but I soon found a spot to sit down, open my laptop and start thinking. I began looking at the work I'd done on the Computus Engine up till now. I've spent years reading up on calendar systems and astronomy and prototyping bits of this thing along the way. I had lots of pieces of the puzzle; I just hadn't tried fitting them together before. So the plan was build a deep zoom for time in a weekend. Or at least see how far along that road I could get.
Later in the day I had a chance to catch up with a few of the speakers. Ever since it struck me last year I've been asking just about everyone I meet the same question. The mother of all temporal standards ISO8601 does not support non-Gregorian dates. What format do you use to store data about events that happened prior to the Gregorian calendar? Mano Marks from Google seemed well placed to answer this. In addition to his expertise in geo-data he also holds a degree in Eastern European history. He suggested the proleptic Gregorian as the most practicable solution. I asked the same of Dan Pett - archaeological data largely pre-dates the Gregorian, what do you use? Again, he suggested proleptic Gregorian. Maybe that's the answer but it feels like a hack to me. It's also error-prone - there has to be a cleaner way.
I kicked off my hack with a quick bit of MVC structure using RobotLegs and Signals. To begin I took my AS3 Timekeeper class and built a Signals version of it. The thinking behind this is that the current version instantiates a new TimekeeperEvent every tick. Instantiation is expensive so a Signals implementation should offer better performance. Next I built a TimeModel for the timeline. This model wraps the SignalsTimekeeper which acts as the central point of the timeline. The model has a radius which then gives you the extents of your viewable timeline.
With the TimeModel working I set to rendering the view. I began with the rather clunky infinite timeline demo I put together a few years ago. The first thing to go was the labels code - this never worked properly anyway. In went some MinimalComps and an ObjectPool. I extended the timeline out into millions of years, and then billions of years ago. I still can't be sure if this works properly as Number get a little funky at such big values.
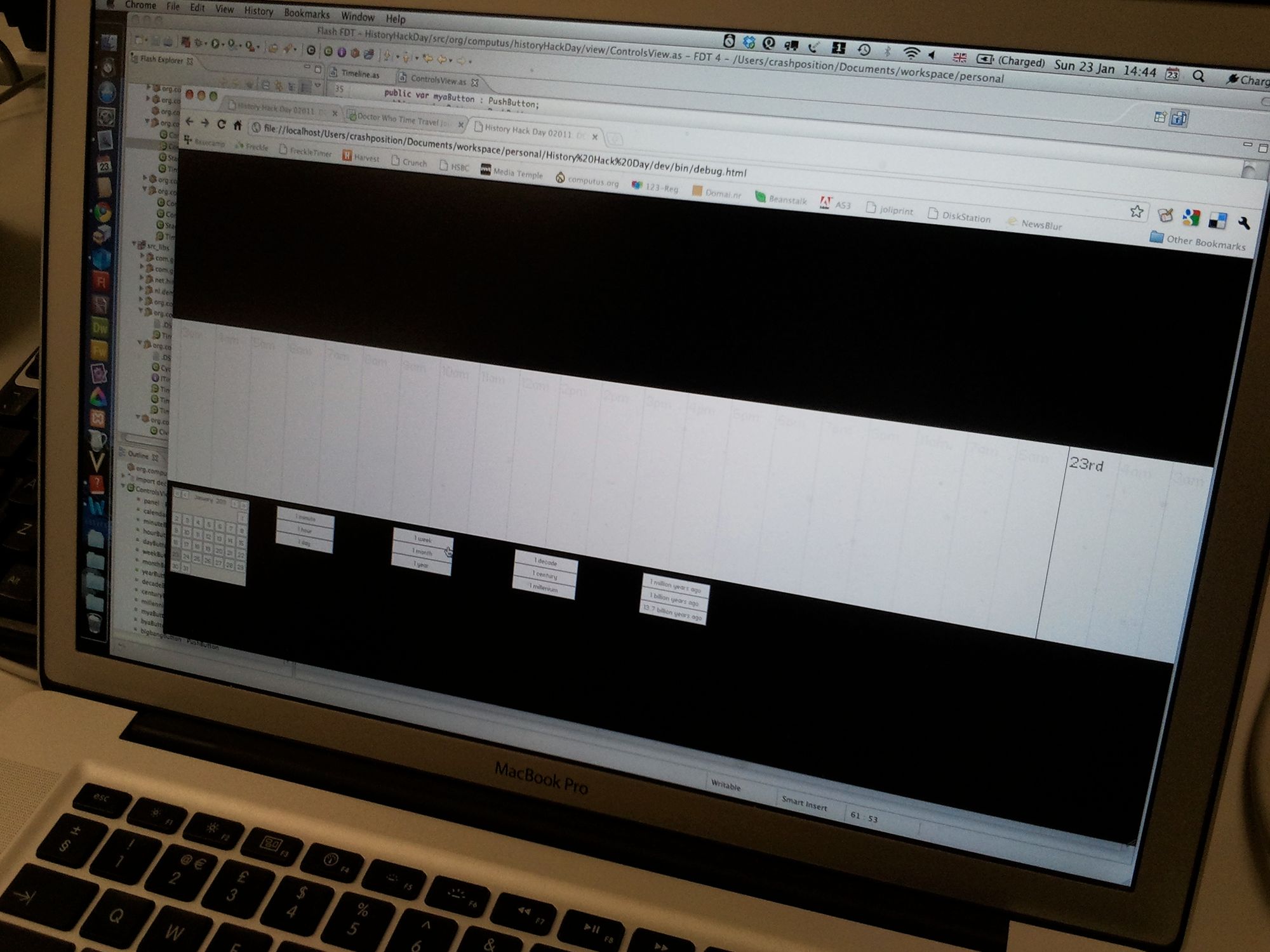
With the label renderer still buggy I crashed on the floor for a few hours. Pro-tip from Hack Day regular Jeremy Keith - bring an inflatable mattress. Within 10 minutes of coding the next morning I nailed the renderer bug and we were off again. With less than an hour to go I went looking for data to put on the timeline. Given the location, what better data source than The Guardian's wonderful crowd-sourced Dr Who journey data. Now I'm an optimistic guy, but even I realised I wasn't going to pull this off. It was round about this point I did a quick Audioboo interview with Steve Lawson from Amplified.
I had of course set my expectations laughably high but I did have something presentable by end of play and quite a lot of good progress came out of it. Unfortunately I had to cut my Hack Day short and ended up missing much of the final presentations. Jeremy has a great roundup of all the projects on his blog though, and there are some photos of the day on Flickr. I really enjoyed History Hack Day and my overall impression was of smart engaged people working on interesting creative projects. Great fun.



